[ SQL ] 순위를 정해주는 함수들(RANK,DENSE_RANK,ROW_NUMBER)
순위를 정해주는 3가지 함수에 대해서 포스팅해볼려고 한다.
자주 사용하지는 않지만, 알고 있으면 다 피와살이 된다.
사용하는 방법은 똑같고, 결과값이 조금씩 다르다.
사용한 DBMS : ORACLE
SQL 클라이언트 : DBeaver
빠른 이해를 위해 임시 데이터로 EMPLOYEE_TEST 테이블의 토트넘 선수들을 넣었다.
CREATE_DT : 해당 데이터를 넣은 시간
PRICE : 선수 값 (전혀 현실고증된 것 없고, 걍 임의의 값을 넣었다.)

1. RANK()
- 해당 컬럼의 값이 동일값이면 같은 순위로 배정한다.
- 그 후 다음 순위의 값은 그 전 같은 순위의 갯수만큼 제외하고 시작한다.
[ 기본 구조 ]
SELECT A.*, RANK() OVER((PARTITION BY [그룹화할 컬럼]) ORDER BY [컬럼] (DESC)) RN
FROM [TABLE_NAME] A
-- RN, A는 임의의 이름PARTITION BY는 GROUP BY랑 같은 것이라고 생각하면 된다. 굳이 필요없다면 생략도 가능하다.
[ 예시 ]

PRICE 컬럼을 내림차순(DESC)으로 하여 SELETE한 모습이다.
RN 컬럼이 RANK() 순위값인데, 동일한 PRICE는 같은 순위로 지정하였고,
2위가 2명이기 때문에 3위없이 바로 4위로 넘어가는 것을 볼 수 있다. (4→6 도 동일)
2. DENSE_RANK()
- RANK()랑 동일하게 해당 컬럼의 값이 동일값이면 같은 순위로 배정한다.
- 단, 다음순위의 값은 이전 순위 중복값의 갯수랑 상관없이 다음 순서로 이어진다.
[ 기본 구조 ]
SELECT A.*, DENSE_RANK() OVER((PARTITION BY [그룹화할 컬럼]) ORDER BY [컬럼] (DESC)) RN
FROM [TABLE_NAME] A
-- RN, A는 임의의 이름
PARTITION BY는 GROUP BY랑 같은 것이라고 생각하면 된다. 굳이 필요없다면 생략도 가능하다.
RANK()랑 함수 이름만 틀리고 나머지 구조는 동일하다.
[ 예시 ]

RANK() 에서 했던 예시에서 함수명만 바꿔서 그대로 실행시킨 모습이다.
RN컬럼을 보면 알 수 있듯이 RANK()에서는 2순위가 2개라서 바로 다음순위가 4였지만, DENSE_RANK()는 3순위로 이어진다. (3→4도 동일)
3. ROW_NUMBER()
- DENSE_RANK()에서 조금 더 변경된 형태라고 이해하면 된다.
- 해당 컬럼의 동일값이 있어도 중복순위를 하지않고, 순서대로 순위를 배정한다.
[ 기본 구조 ]
SELECT A.*, ROW_NUMBER() OVER((PARTITION BY [그룹화할 컬럼]) ORDER BY [컬럼] (DESC)) RN
FROM [TABLE_NAME] A
-- RN, A는 임의의 이름PARTITION BY는 GROUP BY랑 같은 것이라고 생각하면 된다. 굳이 필요없다면 생략도 가능하다.
DENSE_RANK()랑 함수 이름만 틀리고 나머지 구조는 동일하다.
[ 예시 ]

- 이전 예시들과 동일하게 함수이름만 변경해서 적용한 모습이다.
- PRICE컬럼이 동일값이여도 순서대로 순위를 배정한 모습이다.
※ PARTITION BY
여기서는 PATITION BY를 한번도 사용하지 않았다.
PATITION BY을 위해 LIVERPOOL 선수도 추가하였다. (PRICE는 무지성으로 넣은 것이다.)
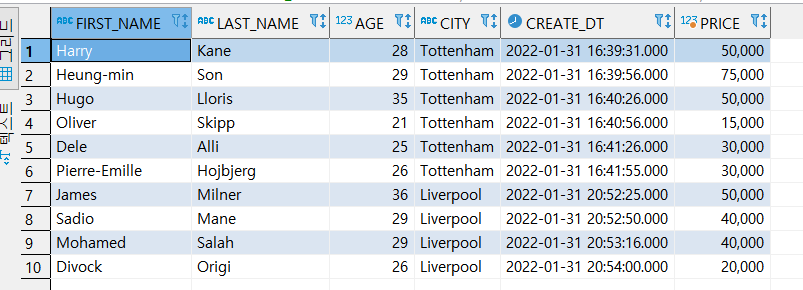
[ 예시 ]
ROW_NUMBER() 함수를 이용해서 PARTITION BY를 CITY로 잡아서 사용했다.
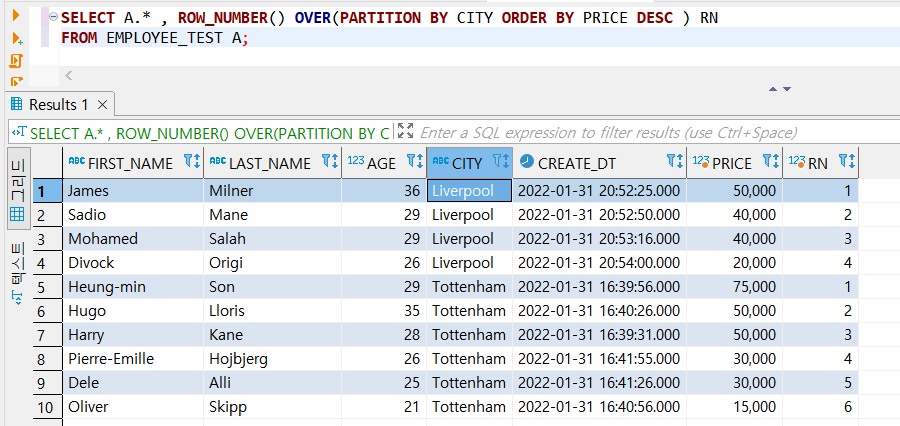
PARTITION BY는 GROUP BY랑 동일한 역할을 한다.
CITY를 한 그룹으로 묶어서 그 안에서 PRICE로 순위를 배정한다.
그래서 이것을 이용해서 중복된 값도 제거할 수 있다.