중복을 제거하고 조회(SELETE)하는 방법은 다양하다.
그 중에서 알고 있는 3가지 방법에 대해서 적어볼려고 한다.
사용한 DBMS : ORACLE
SQL 클라이언트 : DBeaver
빠른 이해를 위해 EMPLOYEE_TEST 테이블의 중복된 데이터를 넣었다.

1. DISTINCT
- 이 방법이 제일 간단하고 자주 사용하는 명령어이다.
[명령어]
SELECT DISTINCT [중복제거할 컬럼]
FROM [TABLE_NAME];
[단일행]

[다중행]

다중행 방법으로 * 사용도 가능하다

* 은 모든행에서 중복을 제거하고 보여주는 방법이다.
CREATE_DT가 1초 차이가 나서 같지 않다고 판단하여 3개의 행이 조회되었다.
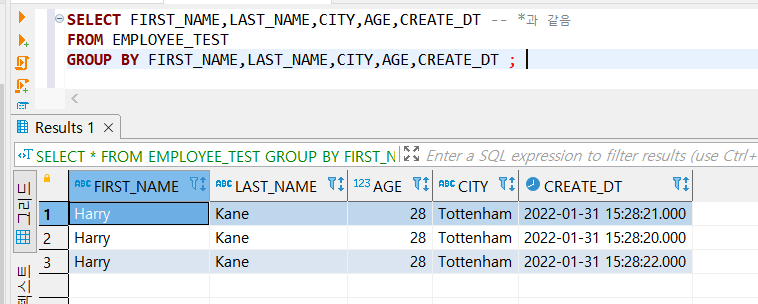
2. GROUP BY 이용
- 동일한 값을 그룹화하면서, 이 방법 또한 유니크한 값만 볼 수 있다.
- 주의할 점은 GROUP BY 에서 그룹화한 컬럼은 꼭 SELECT의 컬럼과 같아야 조회가 가능하다.
SELECT [중복제거할 컬럼]
FROM [TABLE_NAME]
GROUP BY [중복제거할 컬럼];
[단일행]

[다중행]

모든 열을 조회하고 싶다면 GROUP BY의 모든 열을 적어야 가능하다.
(GROUP BY와 SELECT 컬럼을 같아야하기 때문에)
3. ROW_NUMBER 이용
- PARTITION BY 가 GROUP 역할을 하고 RN =1 을 이용하여 중복값을 제거한다.
- ORDER BY에서 컬럼은 정렬한 상태에서 랭크를 정하게 되는데 자세한 내용은 ROW_NUMBER을 이해해야 한다.
SELECT [조회할 컬럼]
FROM ( SELECT A.*,ROW_NUMBER() OVER(PARTITION BY [중복제거할 컬럼] ORDER BY[컬럼]) RN
FROM [TABLE_NAME] A)
WHERE RN=1 ;
[단일행]
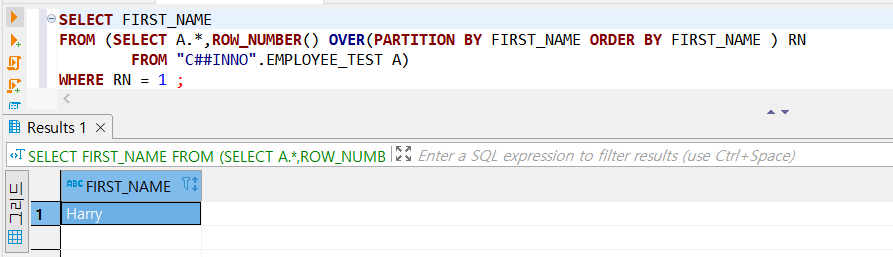
[다중행]

- ORDER BY 컬럼을 CREATE_DT 컬럼 DESC(내림차순)으로 하여 제일 늦게 생성된 행을 조회한 모습이다.
- 이 방법은 거의 사용하지 않았지만 ROW_NUMBER() 함수를 알아두면 좋다.
이렇게 설명한 3가지 방법말고도 중복을 제거하고 조회하는 방법은 정말 다양하므로 꼭 이렇게 할 필요는 없다.
'Languages > SQL' 카테고리의 다른 글
| [ DBeaver ] DBeaver Tibero 추가하기 (0) | 2022.02.13 |
|---|---|
| [ SQL ] 순위를 정해주는 함수들(RANK,DENSE_RANK,ROW_NUMBER) (0) | 2022.01.31 |
| [ SQL ] Tibero comment 추가 (0) | 2022.01.05 |
| [ SQL ] Tibero DML (0) | 2022.01.02 |
| [ SQL ] Tibero DDL (0) | 2021.12.30 |